



Introduction
In the realm of artificial intelligence (AI) and natural language processing (NLP), transformer architectures have revolutionised the way machines understand and generate human language. At the heart of these architectures lies a critical component known as the TransformerDecoderLayer. This article delves into the intricacies of the TransformerDecoderLayer, shedding light on its mechanics, functionality, and wide-ranging applications in the field of AI.
The Evolution of Transformer Architectures
From RNNs to Transformers
Before diving into the TransformerDecoderLayer, it’s essential to understand the context within which it was developed. Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks were the go-to architectures for sequence modelling tasks like machine translation and text generation. However, these architectures faced limitations in capturing long-range dependencies and were computationally expensive.
The introduction of the transformer architecture by Vaswani et al. in the seminal paper “Attention is All You Need” (2017) marked a paradigm shift. Transformers eliminated the need for recurrence and instead relied on self-attention mechanisms, allowing for parallel processing of sequence data. This not only improved computational efficiency but also enhanced the model’s ability to capture contextual information over long sequences.
The Role of Decoder Layers in Transformers
Transformers consist of two main components: the encoder and the decoder. While the encoder processes the input sequence, the decoder is responsible for generating the output sequence. The TransformerDecoderLayer, as the name suggests, is a crucial building block of the decoder. It is responsible for processing the previously generated tokens and attending to the encoder’s output to produce the final output sequence.
Anatomy of the TransformerDecoderLayer
Structure and Components
A typical TransformerDecoderLayer consists of three main sub-layers:
- Self-Attention Mechanism: The first sublayer is the self-attention mechanism, which allows the model to attend to different positions in the input sequence simultaneously. This enables the model to capture dependencies between tokens at different positions in the sequence.
- Encoder-Decoder Attention: The second sub-layer is the encoder-decoder attention mechanism. This layer allows the decoder to focus on specific parts of the encoder’s output, effectively bridging the gap between the input and output sequences.
- Feed-Forward Neural Network (FFN): The third sub-layer is a feed-forward neural network, which is applied to each position separately and identically. This layer introduces non-linearity into the model, enhancing its ability to learn complex patterns.
Multi-Head Attention
A key feature of both the self-attention and encoder-decoder attention mechanisms is the use of multi-head attention. Instead of computing a single attention score, the model computes multiple attention scores (heads) in parallel, each focusing on different aspects of the input sequence. These heads are then concatenated and linearly transformed to produce the final output. Multi-head attention allows the model to capture a richer set of dependencies and relationships within the data.
Residual Connections and Layer Normalisation
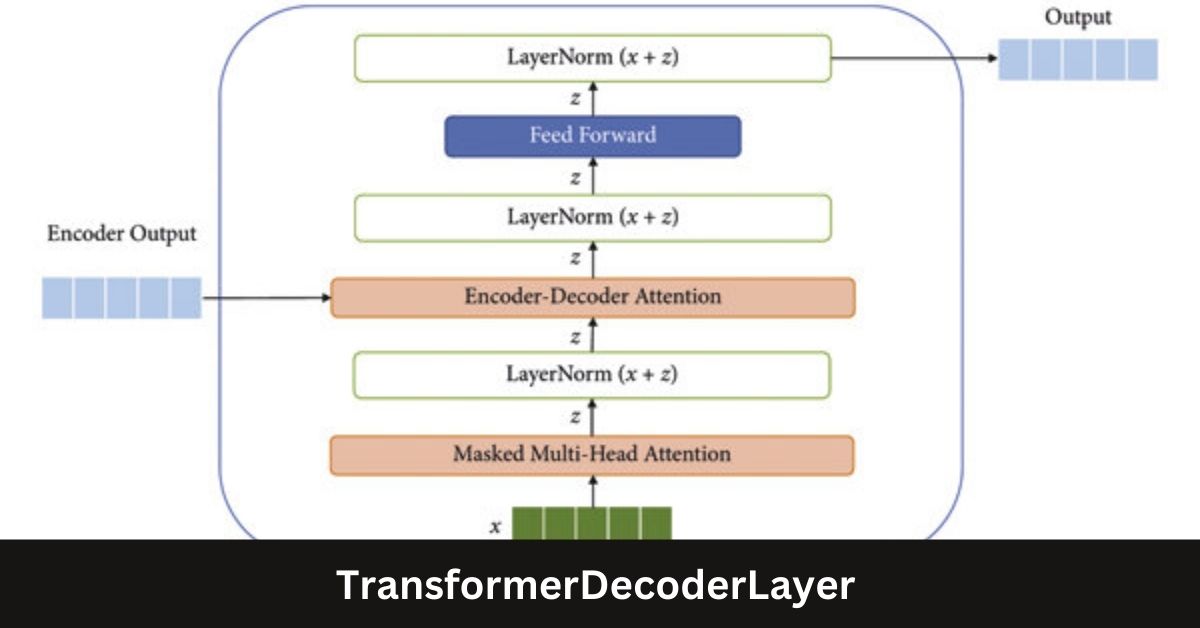
To facilitate training and improve gradient flow, each sublayer in the TransformerDecoderLayer is equipped with residual connections and layer normalisation. Residual connections allow the model to learn residual functions, which helps in mitigating the vanishing gradient problem. Layer normalisation, on the other hand, stabilises the training process by normalising the inputs to each sub-layer.
Position-wise Feed-Forward Networks
The feed-forward neural network in the TransformerDecoderLayer is applied to each token in the sequence independently. This network consists of two linear transformations with a ReLU activation function in between. Despite being applied independently to each position, the parameters of this network are shared across all positions, allowing the model to maintain consistency across the sequence.
The Functionality of the TransformerDecoderLayer
Decoding Process
The decoding process in a transformer model involves generating one token at a time, conditioned on the previously generated tokens and the encoder’s output. The TransformerDecoderLayer plays a pivotal role in this process by attending to both the previously generated tokens (via self-attention) and the encoder’s output (via encoder-decoder attention). This allows the model to produce coherent and contextually relevant output sequences.
Masked Self-Attention
During the decoding process, it is crucial to ensure that the model does not attend to future tokens that have not yet been generated. To achieve this, the self-attention mechanism in the TransformerDecoderLayer employs a technique called masked self-attention. This involves masking the attention scores for future tokens, effectively preventing the model from “peeking” ahead. Masked self-attention ensures that the model generates the output sequence in a left-to-right manner, preserving the causal structure of the sequence.
Beam Search and Sampling Techniques
In practice, the decoding process often involves strategies like beam search or sampling to generate high-quality output sequences. Beam search maintains a fixed number of candidate sequences (beams) at each step, allowing the model to explore multiple possibilities before selecting the most probable sequence. Sampling, on the other hand, introduces randomness into the decoding process by sampling tokens based on their probability distribution. The TransformerDecoderLayer is compatible with both techniques, making it versatile for various applications.
Applications of the TransformerDecoderLayer
Natural Language Processing (NLP)
One of the most prominent applications of the TransformerDecoderLayer is in NLP tasks such as machine translation, text summarization, and text generation. Models like GPT (Generative Pre-trained Transformer) and BART (Bidirectional and Auto-Regressive Transformers) leverage the TransformerDecoderLayer to generate coherent and contextually appropriate text.
Machine Translation
In machine translation, the TransformerDecoderLayer enables the model to translate a sentence from one language to another by attending to both the source sentence (via the encoder-decoder attention) and the previously generated translation (via self-attention). This allows the model to produce translations that are not only grammatically correct but also contextually accurate.
Text Summarization
Text summarization is another area where the TransformerDecoderLayer shines. By attending to the input document and generating a concise summary, the model can produce summaries that capture the key points of the original text while maintaining fluency and coherence.
Text Generation
In text generation tasks, such as chatbots and story generation, the TransformerDecoderLayer plays a crucial role in generating natural and contextually relevant text. The model can generate text one token at a time, attending to the previously generated tokens to ensure consistency and coherence.
Code Generation
Beyond NLP, the TransformerDecoderLayer has also found applications in code generation tasks. Models like OpenAI’s Codex, which powers GitHub Copilot, leverage the TransformerDecoderLayer to generate code snippets based on natural language prompts. The ability of the TransformerDecoderLayer to attend to both the prompt and the previously generated code allows the model to produce syntactically correct and contextually appropriate code.
Speech Recognition and Synthesis
The TransformerDecoderLayer has also been adapted for use in speech recognition and synthesis tasks. In speech recognition, the model can decode audio features into text by attending to the encoder’s representation of the audio input. In speech synthesis, the model can generate audio waveforms by attending to the text input, producing natural-sounding speech.
Image Captioning
Another interesting application of the TransformerDecoderLayer is in image captioning, where the model generates descriptive captions for images. By attending to the visual features of the image (via the encoder-decoder attention) and the previously generated caption tokens (via self-attention), the model can produce captions that accurately describe the content of the image.
Challenges and Limitations
Computational Complexity
One of the main challenges associated with the TransformerDecoderLayer is its computational complexity. The self-attention mechanism, in particular, requires calculating attention scores for every pair of tokens in the sequence, leading to a quadratic time complexity. This can be computationally expensive, especially for long sequences.
Handling Long Sequences
While transformers excel at capturing dependencies over long sequences, they can still struggle with extremely long sequences due to the limitations of self-attention. Various approaches, such as sparse attention and memory-augmented transformers, have been proposed to address this issue, but they come with their own trade-offs.
Interpretability
Another limitation of the TransformerDecoderLayer is the interpretability of its outputs. While the attention mechanisms provide some insights into which parts of the input sequence the model is focusing on, the overall decision-making process can be opaque. This lack of interpretability can be a concern in applications where understanding the model’s reasoning is critical.
Recent Advances and Innovations
Efficient Transformers
Recent research has focused on developing more efficient variants of transformers, such as the Reformer and Reformer, which aim to reduce the computational complexity of self-attention. These models introduce approximations to the self-attention mechanism, making it more scalable for long sequences without significantly compromising performance.
Pre-trained Models and Transfer Learning
The rise of pre-trained models like BERT, GPT, and T5 has further popularized the use of TransformerDecoderLayers. These models are pre-trained on large corpora of text and can be fine-tuned for specific tasks, making them highly versatile and effective across a wide range of applications. The TransformerDecoderLayer plays a crucial role in these models, enabling them to generate high-quality text for various downstream tasks.
Multimodal Transformers
Another exciting development is the emergence of multimodal transformers, which can process and generate data across different modalities, such as text, images, and audio. These models extend the capabilities of the TransformerDecoderLayer by allowing it to attend to multimodal inputs, opening up new possibilities for applications like video captioning, visual question answering, and cross-modal retrieval.
Controlling and Guiding Decoding
Recent innovations have also focused on enhancing the controllability of the decoding process in transformers. Techniques like controlled generation and guided decoding allow users to influence the output of the TransformerDecoderLayer by specifying constraints or preferences. This is particularly useful in applications like creative writing, where the model’s output needs to adhere to specific guidelines or themes.
Future Directions
Towards Universal Transformers
One potential direction for future research is the development of universal transformers that can handle a wide range of tasks with minimal task-specific modifications. By leveraging the versatility of the TransformerDecoderLayer, researchers aim to create models that can seamlessly transition between tasks like text generation, translation, and summarization without requiring extensive fine-tuning.
Improving Interpretability
Addressing the interpretability of transformers is another key area of focus. Developing techniques that can provide more transparent insights into the decision-making process of the TransformerDecoderLayer could help build trust in AI systems, particularly in high-stakes applications like healthcare and legal decision-making.
Integration with Other AI Techniques
The integration of transformers with other AI techniques, such as reinforcement learning and symbolic reasoning, holds promise for creating more powerful and flexible AI systems. By combining the strengths of different approaches, researchers aim to overcome the limitations of the TransformerDecoderLayer and push the boundaries of what AI can achieve.
Conclusion
The TransformerDecoderLayer is a cornerstone of modern transformer architectures, playing a critical role in tasks ranging from natural language processing to code generation and beyond. Its ability to attend to both the input sequence and the previously generated tokens allows it to produce coherent and contextually relevant outputs across a wide range of applications.
Despite its challenges, the TransformerDecoderLayer continues to be at the forefront of AI research and development. As new innovations and techniques emerge, the capabilities of transformers are likely to expand even further, opening up new possibilities for AI-driven solutions in various domains. Whether through more efficient architectures, improved interpretability, or the integration of multimodal data, the future of the TransformerDecoderLayer holds immense potential for advancing the field of AI.


